更新时间:2023-08-30 11:23:57
| StarRocks 又发新版本了,这次动作有点大。
8 月 7 日,StarRocks 3.1 重磅发布。新版本中,StarRocks 将影响性能表现的技术要素全部从存算一体架构引入到了存算分离架构,并针对云原生环境里的易用性、稳定性进行了一系列的优化。 最终的结果是,这一版本的 StarRocks,已经让存算分离架构下的数据查询、导入像在一体架构下一样丝滑,两者性能已基本持平。 如果说 4 个月前 StarRocks3.0 的发布是 StarRocks 向存算分离的一次华丽转身,那么 3.1 版本的发布则宣告StarRocks 已彻底投入云原生湖仓大潮,踏上了新的台阶。 鉴于 StarRocks 历来在性能方面的生猛表现,3.1 版本无疑将对整个行业产生深远影响。 主动拥抱存算分离大势,StarRocks 华丽转身 在 3.0 版本之前,StarRocks 基于存算一体架构构建的产品能力其实已经非常强悍,不仅在技术上拥有傲视业界的性能,在商业上,全场景的 OLAP 解决方案也已得到 260 家市值 70 亿元以上的头部企业用户的认可。 但在存算分离架构越来越成为行业趋势的背景下,StarRocks 并未因既有的成功而迟疑,而是理性看待原有架构中存中的弹性不足、计算资源浪费等问题,毅然选择主动拥抱潮流。 在 3.0 版本中,StarRocks 构建了统一的存算分离平台 StarOS,将存储与计算解耦,从根本上突破了原有架构的局限性。 需要指出的是,尽管存算分离概念并不新鲜,但仅就国内 OLAP 数据库领域而言,在 StarRocks3.0 以前,业界尚无成熟好用的基于存算分离架构的分析型数据库。 StarRocks3.0 一经发布,就引发了全行业的关注,其支撑的低成本、高弹性的云原生 OLAP 方案也在短时间内就吸引了众多用户尝鲜使用,现在更已深度融入到各种分析运维场景之中。 从转身到蜕变,StarRocks 全面拥抱云原生 在从一体架构向分离架构的迁移中,涉及到极其繁杂的架构改造工作. 3.1 版本中,原有架构中主键表模型、自增列属性、时间函数表达式分区等影响到性能体验的技术要素都已全部迁移到新架构。 现在的 StarRocks,在打开 Data cache 的情况下,存算分离架构与存算一体架构在查询性能、导入性能上都已基本持平。 与此同时,3.1 版本还进一步加强了与其它数据组件的连接,新增支持了 Elasticsearch catalog、Paimon catalog,并增强了 Trino 语法兼容性,强化了与Iceberg Catalog 的连通性,这些都使得 StarRocks 在云原生环境下的数据运维变得更加方便。 不忘初心,StarRocks 仍在探测性能极限 StockRocks 的核心优势是极致性能、使用简便、稳定可靠,在新架构下,StarRocks 仍然以性能、易用性、高可用为设计开发导向,坚定有力地提升着产品体验和能力边界。 在新版本中,异步物化视图的使用更简单了,同步物化视图则已支持所有算子,而对分桶功能的优化则让用户不必再关心分桶配置……种种深入到微观运维层面的产品细节,共同构筑出了幅近乎完美的使用图景。 此外,3.1 版本还新增了生成列功能、基数保持 JOIN 表裁剪等加速手段,进一步发掘了新架构下的性能潜力。 毫无疑问,在存算一体架构分析型数据库领域“跑得最快”的 StarRocks,迁移到存算分离架构后,依然是那个让人熟悉的领跑者。 新增核心功能介绍 主键模型表也有了,存算分离架构下查询导入都更丝滑 业界领先的极致性能体验一直是StarRocks 引以为傲的核心优势之一,在向存算分离架构迁移之初,StarRocks 就在极力还原分离架构中的性能优势。 3.1 版本,StarRocks 已经基本将影响性能表现的技术要素全部引入到了分离架构,相对于3.0版本,主键模型表(包括支持部分列更新,但暂不支持持久化索引)、自增列属性 AUTO_INCREMENT、时间函数表达式分区及导入时自动创建分区都已得到完美支持。 此外,专门针对分离架构打造的数据缓存功能在新版本也实现了进一步的优化,通过对热数据缓存范围的个性化调节,即能灵活适配实际使用场景中冷热数据的界定,有效减少冷数据对缓存的占用,从而提升热数据查询性能。 在打开 Data cache 的情况下,存算分离架构与存算一体架构在查询性能、导入性能上都已基本持平。也就是说,StarRocks3.1的存算分离架构,在大幅降低用户存储成本的同时,查询、导入都已经像一体架构一样丝滑。
在 Icerberg 内也能建表了,数据湖分析运维越来越轻松 StarRocks 一直在强调对大数据生态的融合,从一线运维人员的视角出发,细微关注 StarRocks 与其它优秀的、主流的数据组件的连接需求,不断提升易用性,让运维变得越来越轻松。 3.1 版本着重增强了与Iceberg Catalog 的连通性,相对于3.0版本,3.1版本不仅支持对 Parquet 格式的 Icerberg v2 MOR 表的查询访问,还新增了对 Iceberg 元数据的内存+磁盘的两级缓存,有效提升了查询性能,在元数据文件较大的情况下性能升级效果尤其显著。 在写入能力上,则是新增支持了在 Icerberg 内创建数据库、表,并通过 INSERT INTO/OVERWRITE 写入 Parquet 格式数据。通过开放数据格式,用户即可以将 StarRocks 的处理结果无缝接入到生态内的其他组件。 除Iceberg Catalog外,3.1 版本还新增支持了 Elasticsearch catalog[5]、Paimon catalog[6],并进一步增强了 Trino语法兼容性。 执行策略可以单独配置了,物化视图应用场景大大拓展 物化视图因其强大的加速效果,是 StarRocks 的核心功能之一,在历个版本中,StarRocks 都对物化视图进行了大量的优化、升级,不断提升着易用性、灵活性,使其变得更好用、更管用。 在3.1版本中,不管是同步物化视图,还是异步物化视步,同样都作了大量的优化,使用体验和适用场景都有质的提升。 异步物化视图 自 2.4 版本推出异步物化视图以来,这一功能已深度融入用户的查询加速、数仓建模等场景,而StarRocks 也致力于让异步物化视图拥有与内表相同的加速和管理能力,在 3.1 版本中: 支持通过ORDER BY 指定排序键,支持设置colocate_group,进一步利用 StarRocks 原生存储的优化来加速物化视图的查询性能。 支持配置存储介质和降冷时间(storage_medium 、cooldown_time ),方便数据的生命周期管理。 支持不指定分桶,默认采用随机分桶,提升创建物化视图的易用性。 并且为了使异步物化视图更加灵活,在 3.1 版本中: 支持为物化视图的刷新配置会话变量 (Session Variable),用户可以方便地为物化视图配置单独的执行策略,如查询超时时间、并行度、内存限制、是否开启算子落盘等。让物化视图的刷新不受集群整体变量的限制。 支持基于视图(View)创建物化视图,分层建模选择更加灵活。 支持通过 SWAP 原子替换物化视图,从而实现物化视图的 Schema Change 而不影响嵌套的血缘关系。 支持手动激活失效的物化视图,从而在基表重建后仍旧复用历史物化视图。 在查询改写上,StarRocks 致力于让更多场景能够被智能改写,更多发挥物化视图的加速效果。在 3.1 版本中: 新增支持 Join 派生改写、Count Distinct、time_slice 函数等场景的改写,并优化了 Union 改写能力。 新增支持 Stale Rewrite,即在一定时间内允许改写至还未刷新的物化视图上。从而在允许一定数据延迟的实时场景下,通过物化视图提高查询并发。 新增支持 View Delta Join,提升如指标平台、面向主题的宽表场景下的改写能力,降低物化视图的维护成本。 在刷新能力上,在 3.1 版本中: 支持全新同步物化视图刷新接口,同步获取刷新结果。 基于 Hive Catalog 创建的外表异步物化视图可以感知分区变动,按分区增量刷新,加速刷新的同时降低成本。 同步物化视图 拥有同步更新、增量计算能力,并且性能卓越的同步物化视图一直广受 StarRocks 用户喜爱,美中不足的是,历史版本中,其支持的算子还不完整,导致应用场景也受到了一定限制。 在 3.1 版本中,这一局限已不再存在。新版本不仅支持了所有的聚合函数,也支持了CASE-WHEN、CAST、数学运算等表达式。 此外,3.1 版本还支持在单个物化视图内设置多个聚合列,并且可以使用 HINT 来对同步物化视图进行直接查询。 可以说,这一版本的StarRocks,已经大幅拓宽了同步物化视图能力边界。 |
| SQLCREATE MATERIALIZED VIEW v1 ASSELECT b, sum(a + 1) as sum_a1, min(cast (a as bigint)) as min_aFROM base_tableGROUP BY b; |
加速手段更多了,查询性能继续奔跑
众所周知,StarRocks 对查询性能的追求近乎狂热,3.1版本中,这一点又得到了充分体现。
3.1 版本新增了生成列(Generated Column)功能,StarRocks 会根据生成列表达式自动计算表达式的值并在导入时即存储,在查询时会自动判断并进行改写,在无需增加查询复杂性的情况下,再一步提升查询性能。
这一设计尤其适用对 JSON、Array、Map、Struct 等半结构数据的查询加速和对复杂表达式的计算加速。
并且,如果生成列的类型是简单类型,还能利用上 zonemap 等索引,会更进一步加速查询性能。
如下所示,newcol1、newcol2 是两个分别是对 data_array、data_json 列做了一些函数操作的生成列。
| SQLCREATE TABLE t (id INT NOT NULL,data_array ARRAY < int > NOT NULL,data_json JSON NOT NULL,newcol1 DOUBLE ASarray_avg(data_array),newcol2 STRING ASget_json_string(json_string(data_json), '$.a')); |
插入数据时正常插入即可(不用关心生成列),newcol1、newcol2 会自动计算并存储。
| SQLINSERT INTO t VALUES (1, [1,2], parse_json('{"a" : 1, "b" : 2}')),(2, [3,5], parse_json('{"a" : 8, "b" : 3}')) |
查询时也正常查询即可,StarRocks 会自动改写 Query,变成对 newcol1、newcol2 的使用。
| SQLSELECT max(get_json_string(json_string(data_json),”$.a”)) AS a,min(array_avg(data_array)) AS bFROM t; |
同时,StarRocks 优化了主键模型的部分列更新功能,执行 UPDATE [8]语句时会开启列模式(column mode),在更新少部分列但是有大量行的场景下,可提升十倍性能。
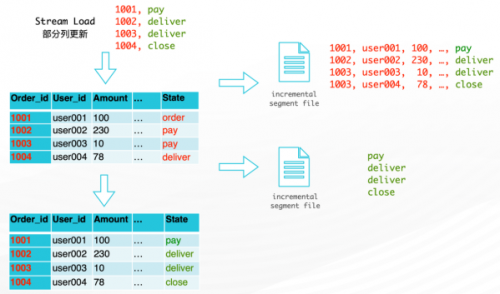
在原来的「行模式」下,部分列更新时,StarRocks 会需要重写整行数据。
在新的「列模式」下,只需要重写更新的列数据即可。
还有,StarRocks 支持了基数保持 JOIN 表(Cardinality-preserving Joins)的裁剪,优化了点查查询性能、统计信息收集、并行 merge 算法、优化内部锁使用的逻辑等等,进一步提升各类细分场景下的查询性能。
其中「基数保持 JOIN 表的裁剪」功能在较多表的星型模型(比如 SSB)和雪花模型(TPC-H)中会有用武之地,当 JOIN 的表存在主键或者外键约束,且可以满足基数保持 JOIN 表裁剪的条件,一些经过裁剪后的 JOIN 的性能能加速 10X 倍以上。
在风控领域进行多种组合的特征选择时,往往采用直接查询由较多表 JOIN 后的 View,此时的裁剪就会起到不错的效果。
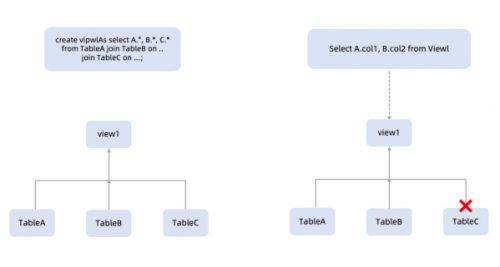
⚠️SELECT view 时,view 中不需要用到的 Table-C 被自动裁剪掉了。使用中需要额外设置一些约束。
Spill To Disk 加强
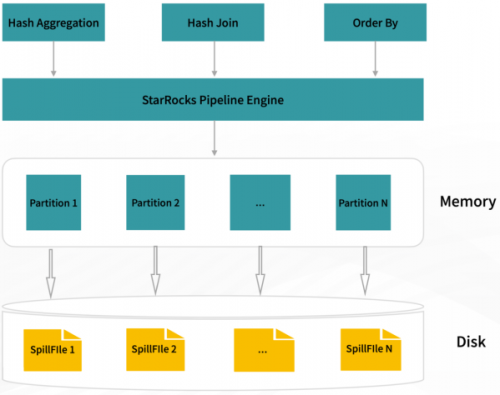
除了卓越的查询性能,在大规模的数据集上查询时的稳定性也是很重要的一个方面。对此,3.1 版本中,StarRocks 正式支持了部分阻塞算子的 Spill(中间数据落盘)能力,当查询中包括聚合、排序或者连接算子时,开启 Spill 功能将允许相关的算子将计算的中间结果缓存到磁盘上,从而降低内存占用,尽量避免查询因内存不足而失败。
在物化视图构建、数据 ETL 处理等内存密集型的场景中,开启 Spill 会极大地提升查询的稳定性。
在 3 个 BE、每个 BE 16core/20G 内存的测试环境中,开启 Spill 功能后,StarRocks 能完整地跑完 TPCH-10TB 测试集。
分桶键可以不用设了,建表与导入更方便
在不断优化查询性能的同时,StarRocks 持续在建表和导入方面提升产品易用性、提供更多实用功能。
在建表时,用户可以配置随机分桶(Random Bucketing)[9]方式(默认),不再需要设置分桶键,StarRocks 会将导入数据随机分发到各个分桶中,同时配合使用 2.5.7 版本起支持的自动设置分桶数量功能(默认),用户可以不再需要关心分桶配置。
| SQLCREATE TABLE site_access(event_day DATE,site_id INT DEFAULT '10',...) DUPLICATE KEY(event_day, site_id)PARTITION BY date_trunc('day', event_day)DISTRIBUTED BY HASH(event_day,site_id) BUCKETS 10; -- 可以不再需要指定 |
在导入数据时,如果数据是存储在 AWS S3/HDFS 上的 Parquet/ORC 格式文件,用户可以很简单地直接采用 INSERT+ FILES()表函数来导入数据,FILES 表函数会自动进行 table schema 推断,做到数据拿来即可 SELECT,用户甚至还可以使用 CTAS + FILES 一键式导入数据,在前期测试数据导入阶段尤其适用。
| SQLCREATE TABLE insert_wiki_edit ASSELECT * FROM FILES('path' = 's3://inserttest/parquet/insert_wiki_edit_append.parquet','format' = 'parquet'); |
同时,关于建表时的分区设置,一般直接设置日期时间字段作为分区列即可,如果用户想要根据自己的数据更灵活地配置,也可以使用 StarRocks 新支持的表达式分区和LIST 分区方式,其中配置表达式分区后,StarRocks 会根据数据和分区表达式的定义规则自动创建分区。
并且,继 3.0 版本中湖分析支持查询 Map、Struct 类型数据后,3.1 版本中导入数据时也支持导入 Parquet/ORC 格式数据中的 Map、Struct 字段类型,为导入提供了更多选项。
StarRocks 在简化建表、简化导入方面将持续地进行端到端的优化,不断提升产品易用性和功能的完善性。
Struct 数据也能用了,半结构化分析能力非常强
3.1 版本中,StarRocks 正式原生支持了 Map 和 Struct 数据类型。除了基于湖上的半结构化数据分析,也支持建表、导入、创建物化视图。同时也补充了 Map 和 Struct 的更多函数,包括标量、聚合以及更多的 Map 高阶函数。
Array 数据类型支持了 Fast Decimal,并且 Array 函数支持了嵌套结构类型 Map、Struct 和 Array。让用户的查询分析体验更加灵活。
并且结合生成列的能力,可以进一步加速对复杂数据类型的计算与查询。例如对 JSON 内的对象的查询、大 ARRAY 的聚合计算等场景,均可以通过生成列在导入时预先完成计算,并在后续查询中通过自动改写完成查询加速。
可以认为,不论是从导入到查询的功能上、还是用生成列来优化性能上,StarRocks 基本完整地支持了 Array、JSON、Map、Struct 这类半结构化数据的能力。
最后,如你希望更加了解 StarRocks 3.1 版本,欢迎观看视频解说。
💬 StarRocks Feature Groups:
StarRocks 社区为了让用户在使用新 features 时能更加得心应手,设立了包含”物化视图“、”湖仓分析“和”存算分离“等的用户群,欢迎小伙伴们入群对特定 feature 进行深入交流!
在这个版本中,117 位贡献者 一共提交了 2785 个 Commits,感谢他们:
stdpain, Astralidea, mofeiatwork, yandongxiao, kevincai, Seaven, hellolilyliuyi, EsoragotoSpirit, Youngwb, andyziye, packy92, sduzh, meegoo, zaorangyang, caneGuy, silverbullet233, chaoyli, LiShuMing, trueeyu, srlch, liuyehcf, ABingHuang, luohaha, amber-create, miomiocat, sevev, letian-jiang, stephen-shelby, zombee0, nshangyiming, satanson, fzhedu, Smith-Cruise, gengjun-git, decster, TszKitLo40, starrocks-xupeng, evelynzhaojie, ZiheLiu, zhenxiao, wyb, rickif, HangyuanLiu, liuzhongjun89, dirtysalt, abc982627271, wanpengfei-git, SilvaXiang, hongli-my, kangkaisen, liuyufei9527, ggKe, xuzifu666, ucasfl, GavinMar, jkim650, JackeyLee007, tracymacding, huzhichengdd, Moonm3n, silly-carbon, imay, szza, you06, leoyy0316, Johnsonginati, smartlxh, xiangguangyxg, vendanner, QingdongZeng3, zhangruchubaba, wxl24life, banmoy, matchyc, predator4ann, huangfeng1993, dengliu, choury, bowenliang123, sebpop, RamaMalladiAWS, dustinlineweber, jiacheng-celonis, chen9t, blanklin030, wangsimo0, howrocks, qmengss, alberttwong, before-Sunrise, chenjian2664, wangruin, kobebryantlin0, wangxiaobaidu11, creatstar, kateshaowanjou, huandzh, mlimwxxnn, goldenbean, Jay-ju, ss892714028, mchades, cbcbq, shileifu, xiaoyong-z, sfwang218, uncleGen, r-sniper, blackstar-baba, ldsink, gddezero, fieldsfarmer, even986025158, idomic, yangrong688, padmejin, zuyu