更新时间:2024-10-08 09:56:31

当下,许多人对AI翻译软件已经不再陌生,这些软件大多依托于文字翻译技术,并逐步融入了AI语音合成功能,来模拟同声传译的体验。例如,科大讯飞同传、有道翻译官和腾讯翻译君等产品,都是这一领域的代表。这类软件的工作原理一般是首先快速识别讲话者的语音,并将其转化为文字,再通过强大的自然语言处理算法对这些文字进行翻译,最后将翻译后每个句子逐个转化成语音并播放,实现“实时翻译”的效果。
然而,这一系列流程不可避免地会带来翻译延迟问题。为了减少延迟,许多翻译软件选择放弃语音播放功能,转而只显示翻译后的文字。这种方式能够实时翻译语音并以“字幕”的形式不断更新,即便由于输入的变化导致翻译结果频繁调整、推倒重来,也不会影响用户的阅读体验。通过取消语音播放,更新后的翻译内容可以更迅速、连续地呈现在用户面前,从而提升整体使用体验。
而AI同声传译模型则使用了完全不同的原理。
得益于近年AI模型的爆发性进展,追求极低延迟的、直接将语音翻译成语音的同声传译模型在2024年开始逐渐出现。这类模型目的是直接或间接地将语音翻译成目标语言的语音。其中,三款表现出色的模型尤其受到关注,也是最接近真人同声传译的方案:Meta(原Facebook)的Seamless-Streaming,中科院计算技术研究所的StreamSpeech,以及知了未来的同声传译v3模型。这类模型的有别于传统的AI翻译软件,它会尝试模仿人类翻译时的行为,不将发言人讲话的内容立马翻译出来,而是边“听”边判断当前发言内容是否足够适合完整、是否需要听取更多的内容才能进行翻译。
Meta在AI领域拥有显著的影响力,尤其是在开源贡献和前沿技术研究方面。其AI研究部门Meta AI多个人工智能领域取得了重要突破,LLaMA(大型语言模型)作为其推出的开源模型,已经在AI研究界广泛使用;并且其推出的开源框架PyTorch已经成为全球AI研究和应用中的主流工具。其同声传译模型Seamless-Streaming此次同样开源,允许任何人访问其核心原理,根据其发表的相关论文显示(https://ai.meta.com/resources/models-and-libraries/seamless-communication-models/),Seamless-Streaming选择使用“EMMA”策略来判断翻译机是否应该立刻翻译听取到的内容还是等待更多内容的输入。在测试使用中,Seamless-Streaming模型做到了3秒左右的延迟的准确翻译,简单来说就是翻译内容滞后于原本发言3秒钟左右。相较于传统AI翻译软件“同声传译”的15秒以上的延迟有了突破性的优化,真正达到了真人同声传译延迟的水准,但可惜准确性相较于传统AI翻译仍有些不足。尤其是中文等复杂语言的翻译测试中,时长出现会错意、听不懂“言下之意”的问题。
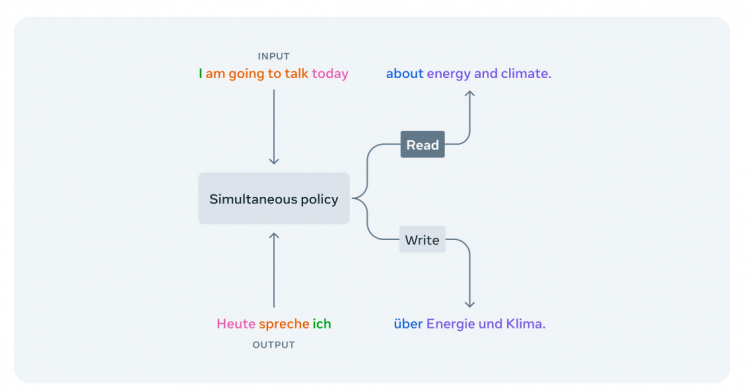
而作为国内最高学术机构和综合性科研中心,中科院同样开源了其关于StreamSpeech模型的研究。根据其发表的论文显示(https://arxiv.org/abs/2406.03049),StreamSpeech主要采用了检查“Alignments”的方式来判断翻译机的等待与否。令人震惊的是,该翻译模型的翻译延迟达到了惊人的0.3秒,值得一提的是,这甚至于人类的平均反应时间相当。这一翻译速度已经远远超过真人能企及的水平,对于真人同声传译员来说,从演讲人说出单词到听到并理解到脑中的时间就已不止0.3秒。可惜目前该模行开源的部分中该模型仅支持英法、英西、英德的翻译,暂时不支持中文。并且在低延迟模型的测试中,翻译的流畅程度有些差强人意,翻译出来的内容更像是“逐字机翻”而非流畅的翻译语句意思。这个问题的出现更多是因为延迟太低,导致翻译机“被迫”翻译一些还没有完成的句子所造成的。

不同于Meta与中科院,知了未来是一支位于伦敦的小型华人研发团队。该团队目前正在融资中,且并尚未开源其模型;其关于此模型公开信息仅有测试体验窗口(https://translate.weil-ai.com/)与论文摘要。根据其公开的论文摘要显示,知了未来的同声传译v3模型相较于前两家,创新之处在于其将“是否等待更多输入”的功能直接交给了翻译模型。现在其正在内测两款模型:小(mini)模型以低延迟为首要目标,根据内测其翻译延迟平均为1-3秒,在发言人讲话清晰时翻译准确率远超上述两款模型。大(large)模型以高精度为特点,翻译延迟平均为2-5秒,而翻译准确与流畅程度达到甚至超越了真人水准,甚至支持中英混合表达、古诗词、方言与流行梗的准确翻译。美中不足的是该模型目前内测名额有限,并且测试火爆经常出现排队使用的状况;其网页翻译功能距离落地产品还有一段距离,目前更像一个“模型展示”的网页。
综上所述,AI同声传译的技术突破已经让更多潜在的可能性进入现实,我们距离电影《流浪地球》中的“两个不同语言的人戴上耳机之后可以正常交流”的场景已经肉眼可见的飞速接近。而当下最接近这个场景的知了未来同声传译等软件还未开始任何的产品落地;到底会先在哪个场景看到它的使用?谁会是第一批用户?成为了交给市场的下一个问题。
在思考这个问题之前,我们回看一下同声传译即将实现的核心功能:将讲话人的声音作为实时输入,将翻译好的语音模拟讲话人的音调作为实时输出。那么给定这个功能下,我们想了一些非常好的例子在这里分享给大家,希望能激发大家的灵感:
一、空乘播报

在国际航班上,乘务员通常被要求会讲两国甚至是多国语言。除了更好的服务旅客,更重要的是在飞行途中对于旅程等信息的播报,例如“入境须知、航班转机信息”等内容需要让不同国家的旅客听明白的话就需要同时说不同的语言。而多语言对于空乘来说确实是一个不小的挑战,但凡口语表达的不清晰就会给旅客造成困扰。而AI同声传译或许在这个时候就可以帮上忙,仅需要空乘会说一种语言,AI负责将其内容以相同的音色传入乘客的耳中,让飞机上来自五湖四海的旅客都可以听清楚听明白、并且让旅途更安心。
二、在线教育

随着在线教育的全球化进程加快,越来越多的教育平台和机构希望吸引来自世界各地的学生。然而,语言差异常常成为学生获取优质教育资源的障碍。尤其是母语为小语种的学生,在学习非母语课程时,往往不仅难以理解,还影响到他们在数学、物理等核心学科的学习能力,许多有天赋的学生因此被埋没。AI同声传译技术恰好能够打破这一壁垒,为讲师提供实时翻译服务,使得无论讲师使用何种语言授课,学生都能同步获取翻译内容,从而在全球化的教育环境中不再受到语言的限制。
AI同声传译技术能够为这些场合提供实时、精准的翻译服务,避免信息传递中的延迟与误解,从而促进更加高效的国际交流与合作。那除此之外,未来还有哪些可能的使用场景?或许下一个突破点,就藏在我们日常生活中的某个细节。随着技术的不断完善,AI同声传译将逐步进入更多的日常应用场景,成为未来全球化沟通不可或缺的一部分。
未来已来,我们拭目以待。









