2022年01月07日整理发布:大数据学习的MYSQL进阶
我给大家讲讲大数据学习中的MYSQL进阶。相信朋友们也应该密切关注这个话题。现在让我们为我的朋友们谈谈大数据学习中的MYSQL进阶。边肖还收集了大数据学习高级版MYSQL的相关信息。我希望你看到后会喜欢。

免费学习推荐:mysql视频教程
文章目录
1影响性能的几个方面1.1硬件1.2服务器系统1.3数据库存储引擎的选择1.4数据库参数配置1.5数据库结构设计和SQL语句(要点)2硬件2.1 CPU资源和可用内存大小2.1.1如何选择CPU2.1.2内存2.1.2.1 MySQL存储引擎2.1.2.2 Tip 2。1.2.3如何选择内存的配置和选择2.2磁盘2.2.1使用传统机器硬盘2.2.2使用RAID提升传统机器硬盘性能2.2.2.1什么是RAID 2 . 2 . 2 . 2 . 2 RAID 2 . 2 RAID 2 . 2 . 1 RAID 2 . 2 . 2 . 2 RAID 12.2.2.3 RAID 5?组ID 2.2.2.2.4 RAID 10 ——常用RAID组2.2.2.2.4 RAID级别的选择2.2.3使用固态存储SSD和PCIe卡2.2.4使用网络存储NAS和SAN2.2.4.1使用网络存储场景2.2.4.2网络性能限制2.3 2.2.4.3网络对性能影响的总结3操作系统对性能的影响3.1 Centos系统参数的优化4文件系统对性能的影响5 MySQL体系结构1影响性能的几个方面
1.1硬件方面
通常个人电脑速度比较慢,我们都说电脑硬件的问题通常是CPU、内存、磁盘IO等因素,所以这个问题也会发生在服务器上。
1.2服务器系统
一般来说,个人电脑的操作系统是windows。不同版本的windows系统性能不同,或者配置了一些参数导致性能不同。服务器系统也是如此,参数的设置也会影响服务器性能。
1.3数据库存储引擎的选择
有了MySQL插件存储引擎,可以根据不同的业务需求选择不同的存储引擎。不同的存储引擎具有不同的特性:
MyISAM:不支持事务表级锁。InnoDB:事务级存储引擎完美支持行级锁事务的ACID特性。1.4数据库参数配置
对于不同的存储引擎,其参数配置是不同的。有些参数对存储引擎影响不大,但有些参数对性能起着决定性的作用。因此,我们根据选择的存储引擎和不同的业务需求来优化参数是非常重要的。
1.5数据库结构设计和SQL语句(重点)
在设计数据库结构时,我们应该考虑将来在数据库上执行什么sql语句来查询和更新表结构。只有这样,才能设计出符合要求的表格结构。查询速度慢是性能差的主要原因,这是我们对数据库表结构设计不合理造成的。对于这种sql,也是最难优化的,因为一旦项目上线,就很难修改数据库表结构。
因此,我们专注于优化数据库性能:
数据库表结构设计
SQL语句的编译和优化
以下是每个方面的详细描述。
2.五金器具
2.1 CPU资源和可用内存大小
2.1.1如何选择CPU
通常在选择CPU的时候,我们都希望CPU的频率和核心数量尽可能的高,但是因为成本或者各种因素,我们只能选择其中的一个。我们应该如何选择最佳解决方案?因此,我们在购买CPU时需要注意几个问题:
我们的应用程序是CPU密集型的吗?如果我们的应用程序是CPU密集型的,为了加快sql处理速度,显然我们需要更好的CPU,而不是更多的CPU。目前MySQL不支持双CPU对同一个SQL的并发处理。我们系统的并发性是什么?如果我们的系统需要更多的吞吐量,那么我们拥有的CPU越多越好。假设我们有40个CPU,可以同时处理40个SQL吗?衡量数据库处理能力的指标:QPS是指同时处理的SQL数量。但是这个索引是以1s为单位处理的SQL数,但是最后一点描述的同时处理是以纳秒为单位的。MySQL通常用于web应用,并发量相对较大。这个时候,CPU的数量比CPU的频率更重要。我们在5.0版本之前使用的MySQL版本,MySQL对多核CPU的支持并不好,对系统的限制非常严重。现在5.65.7版本对多核CPU的支持有了很大的提升。因此,建议使用最新版本的MySQL,以获得更好的性能。选择32位CPU或64位CPU。目前服务器的CPU默认为64位架构,但要注意检查系统是否有32位服务器版本安装在64位上,会严重影响服务器性能。2.1.2内存
内存的大小直接影响数据库的性能。目前内存的效率远高于磁盘。因此,在内存中缓存数据可以大大提高服务器性能。
2.1.2.1常见的MySQL存储引擎
有两种常用的存储引擎:MyISAM和InnoDB。MyISAM:索引存储在内存中,数据存储在硬盘中。
91611763f6b0d6b5ab555bc7a6c-0.png" alt="在这里插入图片描述"/>InnoDB: 索引和数据都保存在内存中从而提高数据库的运行效率。 2.1.2.2 提示虽然内存的数量是越多越好但是对系统的性能影响是有限的。 假如我们数据库的数据有100G那么内存选择在128G左右就可以达到最大的性能了这时如果所有的数据都是热数据那么都会缓存在内存当中没有必要上256G的内存但是选择更大的内存对于操作系统等其他服务的性能也会有相应的提高并且在短期内不用考虑升级内存的问题。对于内存缓存的写操作时可以进行延缓写入减少数据库的压力。 内存在读操作上已经有了很好的支持在写操作上也可以在内存上完成我们最后都需要将数据写入到磁盘中虽然不能避免写入磁盘的操作但是我们可以对写入操作进行延缓将多次写入合并成一次写入减轻数据库的压力。数据库提供了类似的功能可以在缓存池中将多次的写操作合并成一次最终写入磁盘中。
2.1.2.2 提示虽然内存的数量是越多越好但是对系统的性能影响是有限的。 假如我们数据库的数据有100G那么内存选择在128G左右就可以达到最大的性能了这时如果所有的数据都是热数据那么都会缓存在内存当中没有必要上256G的内存但是选择更大的内存对于操作系统等其他服务的性能也会有相应的提高并且在短期内不用考虑升级内存的问题。对于内存缓存的写操作时可以进行延缓写入减少数据库的压力。 内存在读操作上已经有了很好的支持在写操作上也可以在内存上完成我们最后都需要将数据写入到磁盘中虽然不能避免写入磁盘的操作但是我们可以对写入操作进行延缓将多次写入合并成一次写入减轻数据库的压力。数据库提供了类似的功能可以在缓存池中将多次的写操作合并成一次最终写入磁盘中。2.1.2.3 如何选择内存
尽量使用主板能够支持最大频率的内存
组成购买升级每个通道的内存尽量相同品牌、颗粒、频率、电压、校验技术和型号。根据数据库大小选择内存。2.2 磁盘的配置和选择
虽然内存对数据库性能起到很大的作用但是我们不能忽略IO子系统对性能的影响。目前我们常用的磁盘选择有以下4种:
2.2.1 使用传统机器硬盘
特点:存储空间大价格低使用最多最常见读、写较慢
如何选择传统机器硬盘存储容量传输速度访问时间主轴转速物理尺寸2.2.2 使用RAID增强传统机器硬盘的性能
2.2.2.1 什么是RAID
RAID是磁盘冗余队列的简称(Redundant Arrays of Independent Disks)简单来说RAID的作用就是把多个容量较小的磁盘组成一组容量更大的磁盘并提供数据冗余来保证数据完整性的技术。
2.2.2.2 RAID级别
2.2.2.2.1 RAID 0
RAID 0 是最早出现的RAID模式也称之为数据条带。是组件磁盘阵列中最简单的一种形式只需要2块以上的硬盘即可成本低可以提高整个磁盘的性能和吞吐量。RAID 0没有提供冗余或错误修复能力但是实现成本是最低的。但在考虑到数据恢复和可靠性因素RAID 0成为了成本最高的配置因为RAID 0中没有冗余并且数据在损坏的概率在当个磁盘中的还要高。因为数据在任意一个磁盘中损坏都会造成数据的丢失。比如由3块磁盘组成的RAID 0其损坏的几率是单个硬盘的3倍。 因此RAID 0适用于不会单一丢失数据的情况比如:可以随时可以从其他数据库克隆的备库或者某些只需一次性使用的数据库。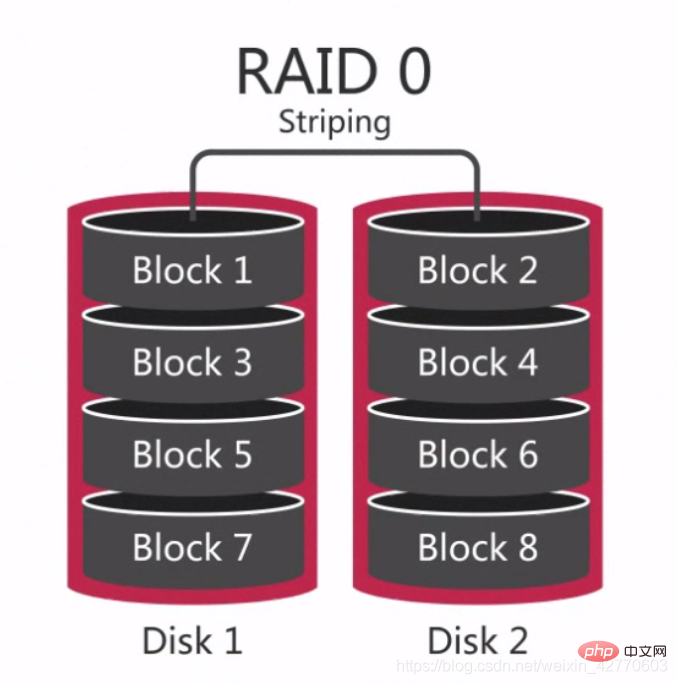 简单来说RAID 0就是将硬盘串联在一起形成更大的磁盘比如:
简单来说RAID 0就是将硬盘串联在一起形成更大的磁盘比如: 并且在并发的过程中可以达到相当于单个硬盘3倍的性能。
并且在并发的过程中可以达到相当于单个硬盘3倍的性能。
RAID 1 又称磁盘镜像原理是把一个磁盘的数据镜像到另一个磁盘上也就是说数据在写入一块磁盘的同时会在另一块限制的磁盘上生成镜像文件在不影响性能情况下最大限度的保证系统的可靠性和可修复性。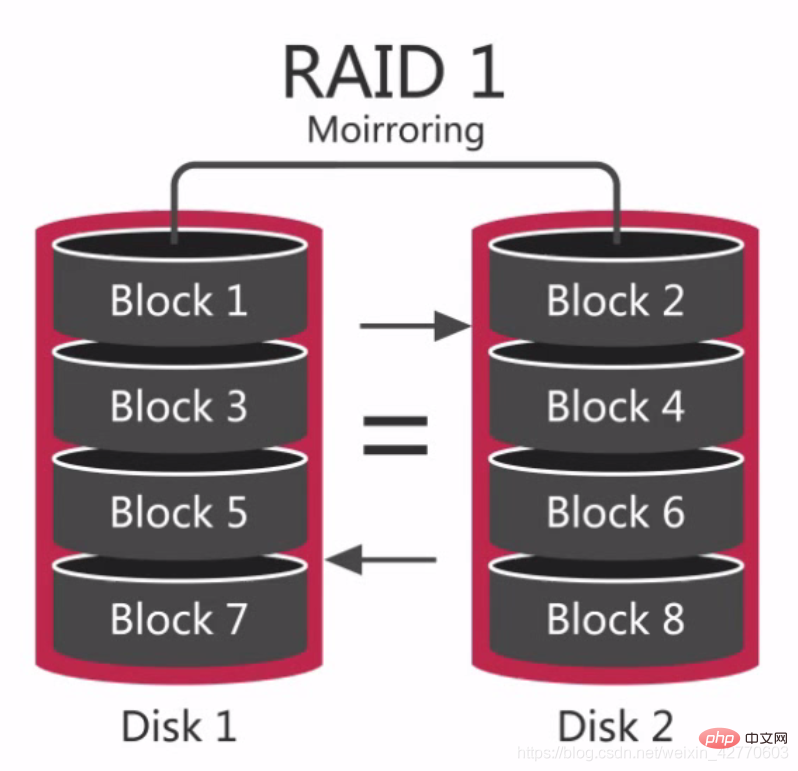 它与RAID 0不同的地方在中间的地方画上了一个等于号。两个磁盘的数据都是一样的具备良好的冗余能力但成本会相应的提高当出现磁盘故障的情况下也可以正常运行但需要即使更换故障的磁盘否则系统也会崩溃。 在更换新的磁盘后数据的同步需要消耗很多时间虽然不会对数据的访问造成影响但系统的性能是会有所下降的。 RAID 1在很多情况下可以提供很好的读性能并且在不同磁盘间冗余数据因此数据冗余性很好。RAID 1在读上比RAID 0 要好因此比较适合在存放日志或类似的工作。
它与RAID 0不同的地方在中间的地方画上了一个等于号。两个磁盘的数据都是一样的具备良好的冗余能力但成本会相应的提高当出现磁盘故障的情况下也可以正常运行但需要即使更换故障的磁盘否则系统也会崩溃。 在更换新的磁盘后数据的同步需要消耗很多时间虽然不会对数据的访问造成影响但系统的性能是会有所下降的。 RAID 1在很多情况下可以提供很好的读性能并且在不同磁盘间冗余数据因此数据冗余性很好。RAID 1在读上比RAID 0 要好因此比较适合在存放日志或类似的工作。
RAID 5 又称之为分布式奇偶校验磁盘阵列。通过分布式奇偶校验块把数据分散到多个磁盘上这样如果任何一个盘数据失效都可以从奇偶校验块中重建。但是如果两块磁盘失效则整个卷的数据都无法恢复。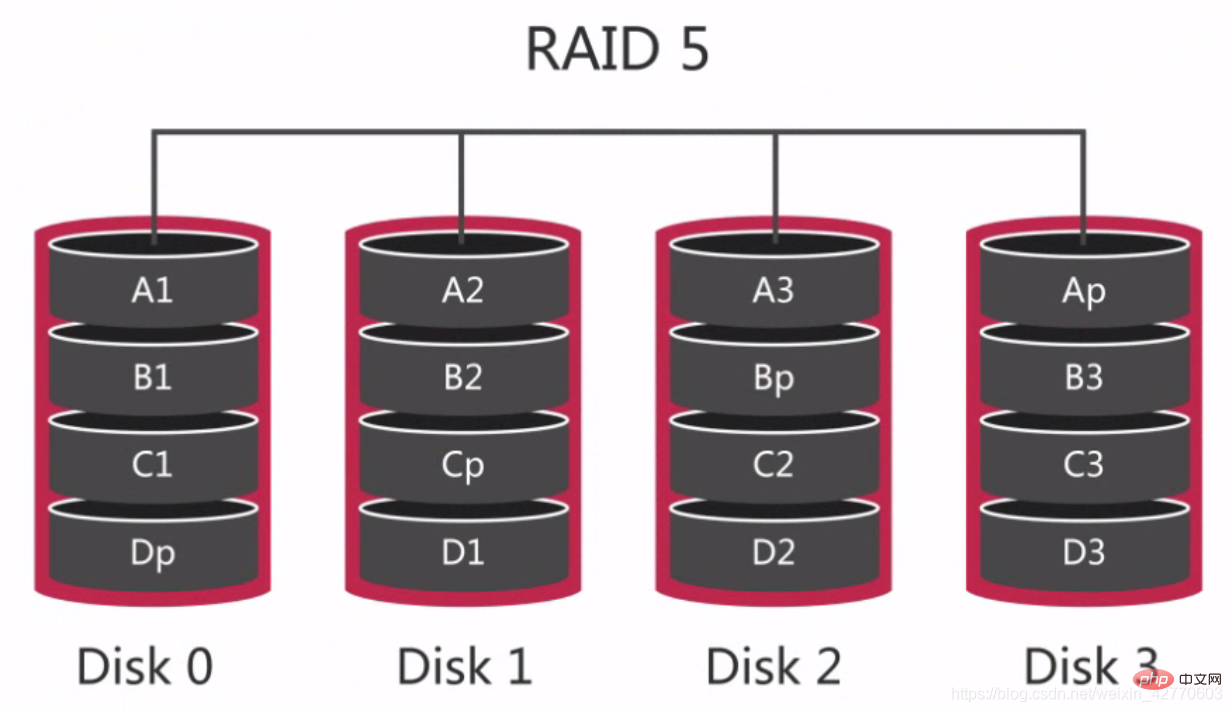 可见每个磁盘中分别有DpCpBpAp如果其中一块磁盘出现问题则可以通过其他三块磁盘的数据和奇偶校验值重新计算出磁盘的数据。 对于RAID 0和RAID 1而言这是最经济的冗余配置因为整个阵列配置只需要1块磁盘的容量就可以了。 在RAID 5上写速度较慢因为每次写都要在磁盘之间进行2次读和2次写以计算存储校验位的数值但是随机读和顺序读都很快因为在读取的时候不需要计算奇偶校验位因此RAID 5 更适合以读为主的数据库业务。 RAID 5发生的最大问题是在磁盘失效的时候因为数据需要重新分配到其他磁盘上这将会严重影响磁盘的性能所以使用RAID 5最好使用在重读的情况下。
可见每个磁盘中分别有DpCpBpAp如果其中一块磁盘出现问题则可以通过其他三块磁盘的数据和奇偶校验值重新计算出磁盘的数据。 对于RAID 0和RAID 1而言这是最经济的冗余配置因为整个阵列配置只需要1块磁盘的容量就可以了。 在RAID 5上写速度较慢因为每次写都要在磁盘之间进行2次读和2次写以计算存储校验位的数值但是随机读和顺序读都很快因为在读取的时候不需要计算奇偶校验位因此RAID 5 更适合以读为主的数据库业务。 RAID 5发生的最大问题是在磁盘失效的时候因为数据需要重新分配到其他磁盘上这将会严重影响磁盘的性能所以使用RAID 5最好使用在重读的情况下。
RAID 10又称分片的镜像。它是对磁盘先做RAID 1之后对两组RAID 1的磁盘再做RAID 0所以对读写都有良好的性能相对于RAID 5重建起来更简单速度也更快。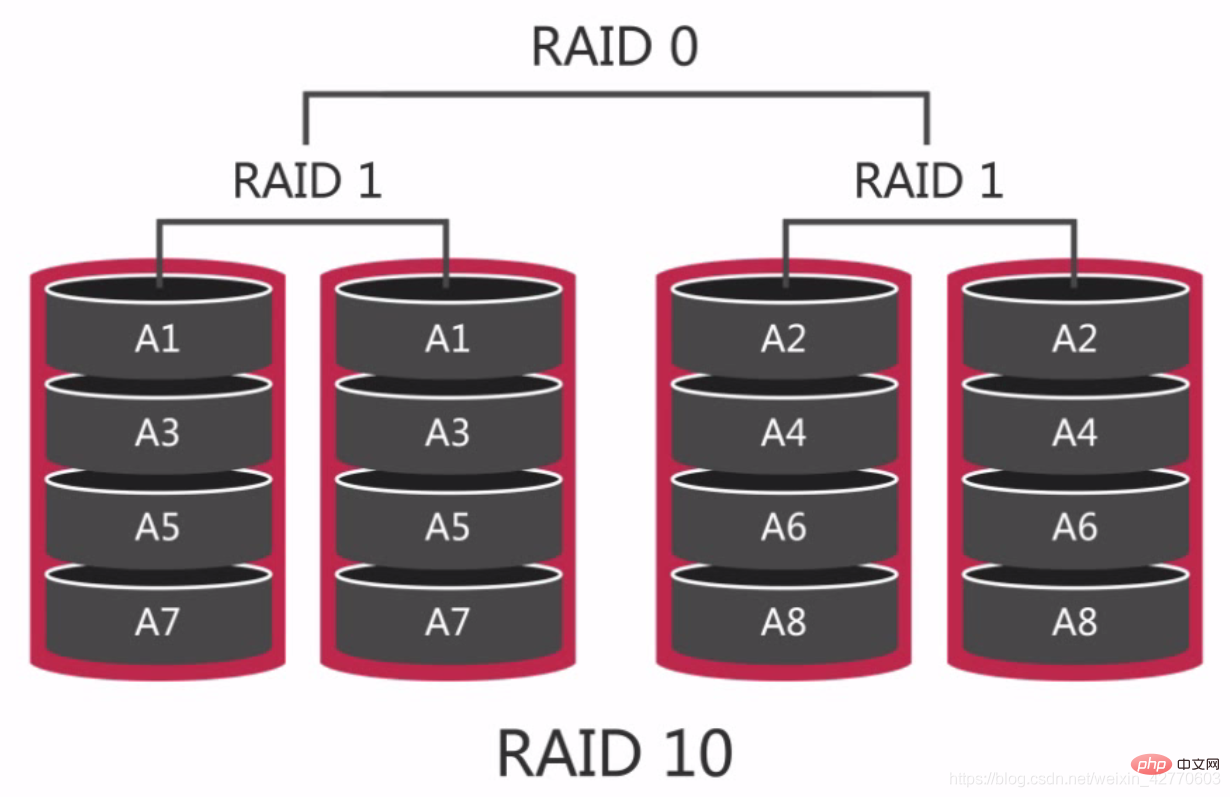 在RAID 10上如果损坏了一个硬盘那么对性能会造成严重的影响因为在读写过程中本来可以在两块相邻的磁盘中同时读取如果损坏了一块那么只能从单台磁盘进行读取因此最坏的情况下我们的性能会降低50%。
在RAID 10上如果损坏了一个硬盘那么对性能会造成严重的影响因为在读写过程中本来可以在两块相邻的磁盘中同时读取如果损坏了一块那么只能从单台磁盘进行读取因此最坏的情况下我们的性能会降低50%。
2.2.3 使用固态存储SSD和PCIe卡
固态存储又称为闪存。 特点:
相比机械磁盘固态磁盘有更好的随机读写性能相比机械磁盘固态磁盘有更好的支持并发相比机械磁盘固态磁盘更容易损坏SSD特点:
使用SATA接口可以替换传统磁盘而不需任何改变SATA接口的SSD同样支持RAID技术固态存储PCIe卡特点:
无法使用SATA接口需要独特的驱动和配置价格相对于SSD更贵但是性能比SSD更好固态存储的使用场景
适用于存在大量随机I/O的场景使用解决单线程负载的I/O瓶颈2.2.4 使用网络存储NAS和SAN
SAN(Strorage Area Network) 和 NAS(Network-Attached Storage) 是两种外部文件存储设备加载到服务器上的方法。
SAN: SAN设备通过光纤连接到服务器设备通过块接口访问服务器可以将其当作硬盘使用。
 SAN的特点:
SAN的特点: NAS: NAS设备使用网络连接通过基于文件的协议如NFS或SMB来访问。
NAS: NAS设备使用网络连接通过基于文件的协议如NFS或SMB来访问。
2.2.4.1 网络存储使用的场景
适合使用在数据库备份。
2.2.4.2 网络性能的限制
网络性能的限制主要是延迟和带宽。
2.2.4.3 网络对性能的影响
网络带宽对性能的影响网络质量对性能的影响 建议:采用高性能和高带宽的网络接口设备和交换机对多个网卡进行绑定增强可用性和带宽尽可能的进行网络隔离2.3 总结
CPU:
64位的CPU一定要工作在64位的系统下对于并发比较高的场景CPU的数量比频率重要对于CPu密集型场景和复杂SQL则频率越高越好内存:
选择主板所能使用的最高频率的内存内存的大小对性能很重要所以尽可能的大I/O子系统:
PCIe -> SSD -> RAID10 -> 磁盘 -> SAN3 操作系统对性能的影响
MySQL适合的操作系统:WindowsFreeBSDSolarisLinux
3.1 CentOS系统参数优化
内核相关参数(/etc/sysctl.conf)
net.core.somaxconn = 65535 对于处于一个监听状态的端口都有一个自己的监听队列这个参数决定了每个端口的监听队列的最大长度。这个参数的默认值可能会比较小对于很大的服务器来说是不够的一般会修改成2048或更大的值。net.core.netdev_max_backlog=65535net.ipv4.tcp_max_syn_backlog=65535 其中backlog这个参数决定了在每个网络接口接收数据包的速率比内核处理机处理快的时候允许被发送到队列中的数据包的最大的数目而另一个参数了是决定了这些还未获得对方连接的这种请求可保存在队中的最大数目。对于超过这个值大小的连接可能会被抛弃所以要同时调大一些。net.ipv4.tcp_fin_timeout = 10 这个参数是用于控制tcp连接处理的等待状态的超时时间。对于连接比较频繁的系统通常由大量的连接数处于等待状态这个参数的设置就是减少连接超时的时间加快tcp的回收速度。同样有对tcp连接有影响的参数有以下两个:net.ipv4.tcp_tw_reuse = 1、net.ipv4.tcp_tw_recycle = 1 这三个参数都是主要加快tcp的回收在高负载的系统下如果tcp连接被占满的话就会出现连接数据库500的错误因此这三个参数的作用是很大的。net.core.wmem_default = 87380、net.core.wmem_max = 16777216、net.core.r0mem_default = 87380、net.core.rmem_max = 16777216 以上4个参数决定了tcp连接接收和发送缓冲区大小的默认值和最大值。对于数据库来说应该把这几个参数的值调整的稍微大一些。net.ipv4.tcp_keepalive_time = 120、net.ipv4.tcp_keepalive_intvl = 30、net.ipv4.tcp_keepalive_probes = 3 以上三个参数用于减少失效连接所占用的tcp系统资源的数量加快资源回收的效率net.ipv4.tcp_keepalive_time是表示tcp发送tcp_keepalive探测消息的时间的间隔单位为秒 用于确认tcp连接是否有效。net.ipv4.tcp_keepalive_intvl用于当探测这个tcp连接没有反应后重新发送探测消息的时间间隔单位为秒net.ipv4.tcp_keepalive_probes表示在认定tcp连接失效之前需要发送多少个tcp_keepalive探测消息。这三个参数的默认值对于一个平常系统来说稍微有点大了所以这里分别对它们改为了小了一些。kernel.shmmax = 4294967295 这个参数是Linux内核参数中最重要的参数之一用于定义单个共享内存段的最大值。注意:这个参数应该设置的足够大以便能在一个共享内存段下容纳下整个的Innodb缓冲池的大小。这个值的大小对于64为Linux系统可取的最大值为物理内存值 - 1 byte建议值为大于物理内存段的一半一般取直大于Innodb缓冲池的大小即可可以取物理内存 - 1 byte。vm.swappiness = 0 这个参数当内存不足时会对性能产生比较明显的影响。这个参数就是告诉Linux系统内核除非虚拟内存完全满了否则不要使用交换区。Linux系统内存交换分区: 在Linux系统安装时都会有一个特殊的磁盘分区称之为系统交换分区。如果我们使用free -m在系统中查看可以看到类似下面的内容其中swap就是交换分区。当操作系统因为没有足够的内存时就会将一些虚拟内存写到磁盘的交换区中这样就会发生内存交换。 在MySQL服务所在的Linux系统上完全禁用交换分区会带来以下两点风险:降低操作系统的性能容易造成内存溢出崩溃或都被操作系统Kill掉增加资源限制(/etc/security/limit.conf)limit.conf这个文件实际上时Linx PAM也就是插入式认证模块的配置文件。 其中比较重要的参数配置就是打开文件数的限制。 结论:把可打开的文件数量增加到了65535个以保证可以打开足够多的文件句柄。 注意:这个文件的修改需要重启服务器后生效。
结论:把可打开的文件数量增加到了65535个以保证可以打开足够多的文件句柄。 注意:这个文件的修改需要重启服务器后生效。
磁盘调度策略(/sys/block/devname/queue/scheduler) 可以使用命令cat /sys/block/sda/queue/scheduler查看当前磁盘所使用的调度策略。下面的noop anticipatory deadline [cfq]为系统默认的cfq调度策略。 在MySQL数据库服务下cfq并不合适是由于在MySQL工作过程中cfq会在队列中插入一些不必要的请求导致很差的响应时间。 除了cfq调度策略还有以下几种策略: noop(电梯式调度策略):
除了cfq调度策略还有以下几种策略: noop(电梯式调度策略): deadline(截止时间调度策略):
deadline(截止时间调度策略): anticipatory(预料I/O调度策略):
anticipatory(预料I/O调度策略): 我们可以输入以下命令来改变磁盘的调度策略:echo schedulerName > /sys/block/sda/queue/scheduler 如:echo deadline > /sys/block/sda/queue/scheduler
我们可以输入以下命令来改变磁盘的调度策略:echo schedulerName > /sys/block/sda/queue/scheduler 如:echo deadline > /sys/block/sda/queue/scheduler
4 文件系统对性能的影响
推荐使用XFS文件系统在EXT3和EXT4下需要配置以下参数: EXT3/4系统的挂载参数(/etc/fstab):
EXT3/4系统的挂载参数(/etc/fstab):
5 MySQL体系结构
体系结构在最上层的叫做客户端这一层代表了可以通过mysql连接协议连接到mysql的客户端比如说PHPJAVAC API.Net以及ODBCJDBC等从这里可以看出这一层并不是mysql体系结构所特有。大多数CS架构的服务都是采用了这一种体系结构。这一层主要是完成了连接处理授权认证和安全等一些功能。每个连接到mysql的客户端都在服务器的进程中拥有一个线程这个连接的查询只会在这个线程中进行执行也就是我们前面说到的每个连接的查询只用到一个CPU的核心。 那么这个体系的第二层大多数的mysql核心服务都在这一层中如下图所示。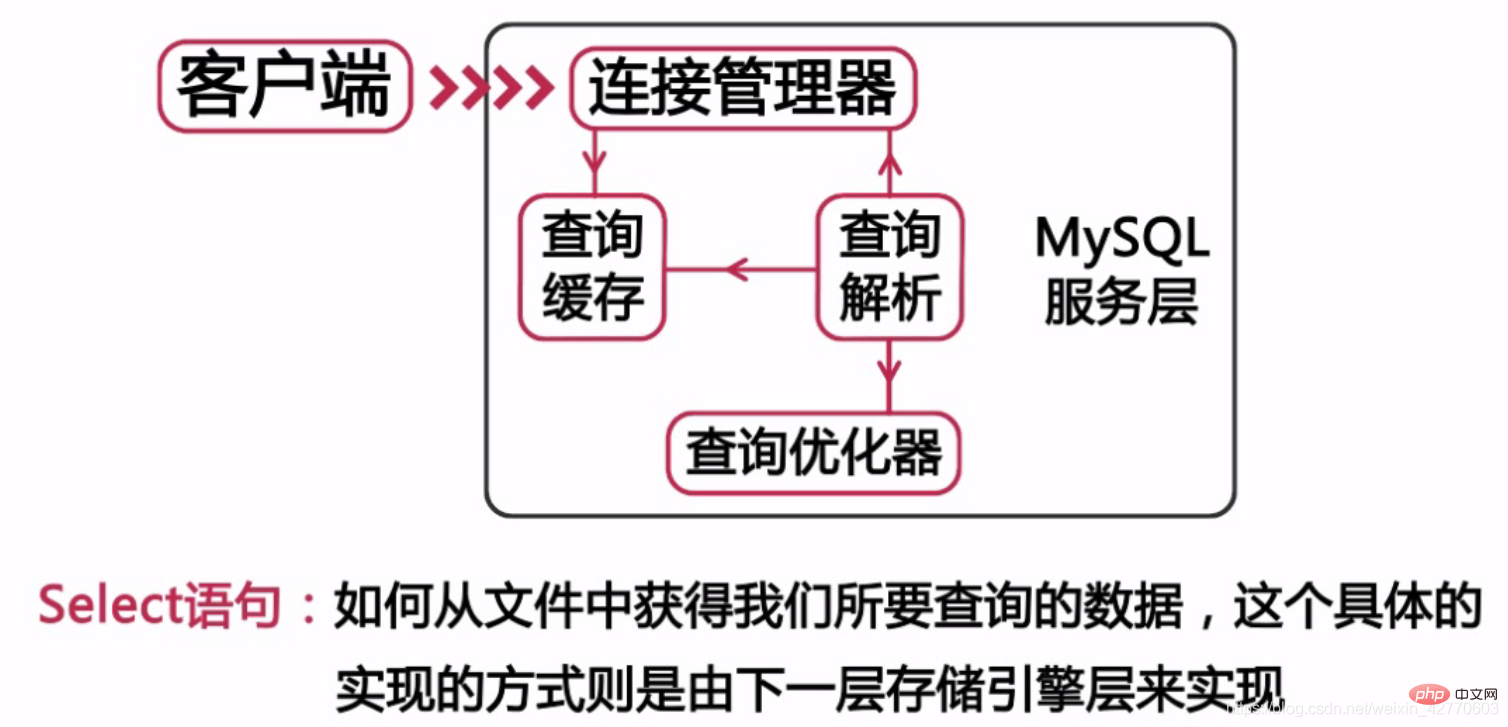 我们常用的DDL或者DML语句都是在这一层上定义的。但是我们只要记住一点就可以了所有跨存储引擎的功能都是在这一层中实现的因为这一层也被称之为服务层。 我们的结构体系的第三层是存储引擎层mysql是一款非常优秀的开源数据库其中定义了一系列了存储引擎的接口只要符合存储引擎的要求我们就可以对mysql开发出一款完全符合自己需要的存储引擎比如我们常用的InnoDB目前mysql支持的存储引擎有很多如下图所示:
我们常用的DDL或者DML语句都是在这一层上定义的。但是我们只要记住一点就可以了所有跨存储引擎的功能都是在这一层中实现的因为这一层也被称之为服务层。 我们的结构体系的第三层是存储引擎层mysql是一款非常优秀的开源数据库其中定义了一系列了存储引擎的接口只要符合存储引擎的要求我们就可以对mysql开发出一款完全符合自己需要的存储引擎比如我们常用的InnoDB目前mysql支持的存储引擎有很多如下图所示: 注意:存储引擎是针对于表的而不是针对于库的(一个库中的不同表可以使用不同的存储引擎) 下面我们选一些比较常用的存储引擎进行简单的说明mysql所使用的存储引擎会对数据库的性能产生直接的影响还希望各位能仔细的了解存储引擎的一些特点完了之后才使用存储引擎。
注意:存储引擎是针对于表的而不是针对于库的(一个库中的不同表可以使用不同的存储引擎) 下面我们选一些比较常用的存储引擎进行简单的说明mysql所使用的存储引擎会对数据库的性能产生直接的影响还希望各位能仔细的了解存储引擎的一些特点完了之后才使用存储引擎。
更多相关免费学习推荐:mysql教程(视频)
以上就是大数据学习的MYSQL进阶的详细内容!
来源:php中文网
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
万象汽车试驾,轻松搞定试驾。只需几步,即可开启您的驾驶体验之旅。首先,通过官网或APP预约试驾时间,选择心...浏览全文>>
-
北汽瑞翔试驾流程主要包括以下几个步骤:首先,客户到达4S店后,由销售顾问接待并了解客户需求。随后,销售顾...浏览全文>>
-
试驾MG4 EV全攻略:MG4 EV是一款主打年轻、智能与续航的纯电车型。外观时尚,车身紧凑,适合城市通勤。内饰...浏览全文>>
-
预约试驾奥迪SQ5 Sportback,可线上与线下结合操作。首先,访问奥迪官网或官方APP,选择“试驾预约”,填写个...浏览全文>>
-
红旗试驾预约通常需要以下条件:1 年龄要求:申请人需年满18周岁,部分门店可能要求20岁以上。2 驾驶证...浏览全文>>
-
特斯拉试驾全攻略试驾特斯拉前,建议提前在官网预约,选择最近的体验中心。到店后,工作人员会引导你完成基础...浏览全文>>
-
宝马预约试驾全攻略想要体验宝马的驾驶乐趣?提前预约试驾是关键。首先,访问宝马官网或使用“宝马中国”官方A...浏览全文>>
-
道郎格试驾,感受豪华与科技的完美融合。一进入车内,高端质感扑面而来,真皮座椅、精致内饰,尽显奢华。智能...浏览全文>>
-
预约奇瑞新能源试驾,新手可按以下步骤操作:1 选择车型:登录奇瑞官网或官方App,浏览新能源车型,如艾瑞...浏览全文>>
-
奔驰GLE试驾预约,开启非凡旅程。作为豪华SUV的典范,GLE集优雅设计与强大性能于一身,为您带来前所未有的驾驶...浏览全文>>
- 特斯拉试驾全攻略
- 宝马预约试驾全攻略
- 奔驰GLE试驾预约,畅享豪华驾乘,体验卓越性能
- 零跑C16试驾全攻略
- 试驾海豚,轻松几步,畅享豪华驾乘
- 奇瑞预约试驾的流程及注意事项
- 小鹏G7试驾,新手必知的详细步骤
- 如何在 IPHONE 16E 和 IPHONE 16 之间进行选择
- 这个隐藏的 ANDROID 设置可以释放大屏幕的全部潜力
- 三星 ONE UI 7 更新:比预期更早到来
- IPHONE 15 PRO 和 PRO MAX 将很快获得视觉智能
- 使用这些必备的 ANDROID 应用程序改变你的主屏幕
- PS5 PRO 销量与 PS4 PRO 竞争
- 超薄 Galaxy S25 Edge揭晓其新功能
- Android 15 QPR2 Beta 2.1 将修复与崩溃相关的问题
- Garmin 的 Fenix 7 Pro Sapphire Solar 降至 591 美元
- Galaxy S25 Ultra 的 S Pen 可能会失去蓝牙功能
- 惠普在 CES 上推出搭载 Copilot+ 的全新一体机和迷你电脑
- 首批 Galaxy S25 系列壁纸来了 但只有两张
- 1,000 马力的 911 Turbo S GT-R 与杜卡迪一较高下