2022年01月15日整理发布:介绍python爬取网页
我来告诉你一些关于python抓取网页的事情。相信朋友们也应该密切关注这个话题。现在,让我们告诉你一些关于python抓取网页的事情。边肖还收集了关于python抓取网页的相关信息。我希望你看到后会喜欢。

之前也写过很多关于爬虫在网上爬网页的代码。最近还是想把写好的爬虫录下来给大家使用!
代码分为四个部分:
第一部分:找一个网站。
我还是在这里找到了一个比较简单的网站,叫做https://movie.douban.com/top250? start=
你可以登录看看。这里可能有一些库没有安装。首先,上图显示您可以安装抓取网页所需的库。其中我这次用的库有:bs4urllibxlwt,re。
(免费学习推荐:python视频教程)
数字
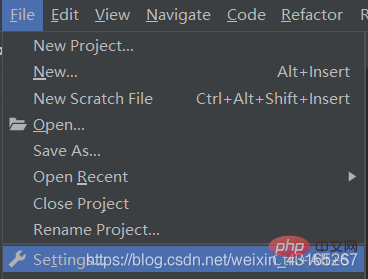
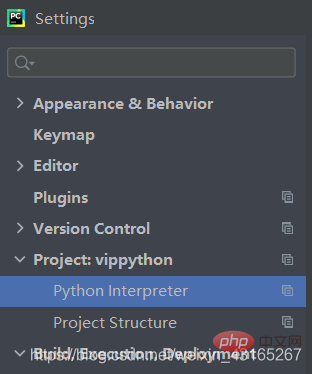
在这里选择文件-设置-项目-然后选择左下角的加号自己安装需要的文件。
以下代码是抓取网页的源代码:
导入URL lib . request from bs4 import beautulsuupimport xlwtimport redef main :
#抓取网页
base URL=' https://movie . douban.com/top 250?开始='
datalist=getData(baseurl)
Savepath='豆瓣电影Top250.xls '
#保存数据
保存数据(数据列表,保存路径)
# AskURl(' https://movie . douban.com/top 250?Start=1')#电影细节规则Findlink=重新编译。*?)' ')#创建查找img src=re.compile (r' img)的规则。* src='(。*?)'',Re。S) #将换行符与字符匹配#电影标题Fintitle=re . pile(r ' span class=' title '(。*)/span') #影片的评分find nating=re.compile(r ' span class=' rating _ num ' property=' v 3360 average '(。*)/span') #找到的评估者数量=重新编译(r 'span (\ D*)个人评估/span') #找到一般情况Findinq=重新编译(r' span class=' inq '(。*)/span') #找到电影的相关内容Findbb=re.compile (r' p class=' '(。*?)/p ',re。S)#re。忽略换行符第二部分:抓取网页。
def getData(baseurl):
datalist=[]
对于(0,10):范围内的I
url=baseurl字符串(i*25)
Html=askURL(url) #保存获得的网页源代码。
#解析网页
soup=美化输出(html,‘html . parser’)
汤里的食物。find _ all ('p ',class _=' item') : #找到符合要求的字符串组成列表。
#打印(项目)#测试以查看电影信息
数据=[]
项目=字符串(项目)
Link=re.findall (findlink,item) [0] # Re库用于查找指定的字符串。
data.append(link) imgSrc = re.findall(findImgSrc, item)[0] data.append(imgSrc) #添加图片 titles = re.findall(finTitle, item) # if (len(titles) == 2): ctitle = titles[0] #添加中文名 data.append(ctitle) otitle = titles[1].replace("/", "") #replace("/", "")去掉无关的符号 data.append(otitle) #添加英文名 else: data.append(titles[0]) data.append(' ')#外国名字留空 rating = re.findall(findReating, item)[0] #添加评分 data.append(rating) judgeNum = re.findall(findJudge,item) #评价人数 data.append(judgeNum) inq = re.findall(findInq, item) #添加概述 if len(inq) != 0: inq = inq[0].replace(".", "") #去掉句号 data.append(inq) else: data.append(" ") #留空 bd = re.findall(findBb,item)[0] bd = re.sub('<br(\s+)?/>(\s+)?',' ', bd) #去掉br 后面这个bd表示对bd进行操作 bd = re.sub('/', ' ', bd) #替换/ data.append(bd.strip) #去掉前后的空格strip datalist.append(data) #把处理好的一部电影放入datalist当中 return datalist第三部分:得到一个指定的url信息。
#得到指定的一个url网页信息def askURL(url): head = { "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36"} request = urllib.request.Request(url,headers=head) # get请求不需要其他的的而post请求需要 一个method方法 html = "" try: response = urllib.request.urlopen(request) html = response.read.decode('utf-8') # print(html) except Exception as e: if hasattr(e,'code'): print(e.code) if hasattr(e,'reason'): print(e.reason) return html第四部分:保存数据
# 3:保存数据def saveData(datalist,savepath): book = xlwt.Workbook(encoding="utf-8", style_compression=0) sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) col = ('电影详情链接', '图片链接', '影片中文名', '影片外国名', '评分', '评价数', '概况', '相关信息') for i in range(0,8): sheet.write(0,i,col[i]) #列名 for i in range(0,250): print("第%d条"%i) data = datalist[i] for j in range(0,8): sheet.write(i+1,j,data[j]) book.save(savepath) #保存这里大家看一下代码关于代码的标注我写的还是挺清楚的。
其中关于学习这个爬虫还需要学习一些基本的正则表达式当然python基本的语法是不可少的希望对大家有帮助吧。
相关免费学习推荐:python教程(视频)
以上就是介绍python爬取网页的详细内容!
来源:php中文网
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
万象汽车试驾,轻松搞定试驾。只需几步,即可开启您的驾驶体验之旅。首先,通过官网或APP预约试驾时间,选择心...浏览全文>>
-
北汽瑞翔试驾流程主要包括以下几个步骤:首先,客户到达4S店后,由销售顾问接待并了解客户需求。随后,销售顾...浏览全文>>
-
试驾MG4 EV全攻略:MG4 EV是一款主打年轻、智能与续航的纯电车型。外观时尚,车身紧凑,适合城市通勤。内饰...浏览全文>>
-
预约试驾奥迪SQ5 Sportback,可线上与线下结合操作。首先,访问奥迪官网或官方APP,选择“试驾预约”,填写个...浏览全文>>
-
红旗试驾预约通常需要以下条件:1 年龄要求:申请人需年满18周岁,部分门店可能要求20岁以上。2 驾驶证...浏览全文>>
-
特斯拉试驾全攻略试驾特斯拉前,建议提前在官网预约,选择最近的体验中心。到店后,工作人员会引导你完成基础...浏览全文>>
-
宝马预约试驾全攻略想要体验宝马的驾驶乐趣?提前预约试驾是关键。首先,访问宝马官网或使用“宝马中国”官方A...浏览全文>>
-
道郎格试驾,感受豪华与科技的完美融合。一进入车内,高端质感扑面而来,真皮座椅、精致内饰,尽显奢华。智能...浏览全文>>
-
预约奇瑞新能源试驾,新手可按以下步骤操作:1 选择车型:登录奇瑞官网或官方App,浏览新能源车型,如艾瑞...浏览全文>>
-
奔驰GLE试驾预约,开启非凡旅程。作为豪华SUV的典范,GLE集优雅设计与强大性能于一身,为您带来前所未有的驾驶...浏览全文>>
- 特斯拉试驾全攻略
- 宝马预约试驾全攻略
- 奔驰GLE试驾预约,畅享豪华驾乘,体验卓越性能
- 零跑C16试驾全攻略
- 试驾海豚,轻松几步,畅享豪华驾乘
- 奇瑞预约试驾的流程及注意事项
- 小鹏G7试驾,新手必知的详细步骤
- 如何在 IPHONE 16E 和 IPHONE 16 之间进行选择
- 这个隐藏的 ANDROID 设置可以释放大屏幕的全部潜力
- 三星 ONE UI 7 更新:比预期更早到来
- IPHONE 15 PRO 和 PRO MAX 将很快获得视觉智能
- 使用这些必备的 ANDROID 应用程序改变你的主屏幕
- PS5 PRO 销量与 PS4 PRO 竞争
- 超薄 Galaxy S25 Edge揭晓其新功能
- Android 15 QPR2 Beta 2.1 将修复与崩溃相关的问题
- Garmin 的 Fenix 7 Pro Sapphire Solar 降至 591 美元
- Galaxy S25 Ultra 的 S Pen 可能会失去蓝牙功能
- 惠普在 CES 上推出搭载 Copilot+ 的全新一体机和迷你电脑
- 首批 Galaxy S25 系列壁纸来了 但只有两张
- 1,000 马力的 911 Turbo S GT-R 与杜卡迪一较高下